In a recent project, we were tasked with designing how we would replace a
Mainframe system with a cloud native application, building a roadmap and a
business case to secure funding for the multi-year modernisation effort
required. We were wary of the risks and potential pitfalls of a Big Design
Up Front, so we advised our client to work on a ‘just enough, and just in
time’ upfront design, with engineering during the first phase. Our client
liked our approach and selected us as their partner.
The system was built for a UK-based client’s Data Platform and
customer-facing products. This was a very complex and challenging task given
the size of the Mainframe, which had been built over 40 years, with a
variety of technologies that have significantly changed since they were
first released.
Our approach is based on incrementally moving capabilities from the
mainframe to the cloud, allowing a gradual legacy displacement rather than a
“Big Bang” cutover. In order to do this we needed to identify places in the
mainframe design where we could create seams: places where we can insert new
behavior with the smallest possible changes to the mainframe’s code. We can
then use these seams to create duplicate capabilities on the cloud, dual run
them with the mainframe to verify their behavior, and then retire the
mainframe capability.
Thoughtworks were involved for the first year of the programme, after which we handed over our work to our client
to take it forward. In that timeframe, we did not put our work into production, nevertheless, we trialled multiple
approaches that can help you get started more quickly and ease your own Mainframe modernisation journeys. This
article provides an overview of the context in which we worked, and outlines the approach we followed for
incrementally moving capabilities off the Mainframe.
Contextual Background
The Mainframe hosted a diverse range of
services crucial to the client’s business operations. Our programme
specifically focused on the data platform designed for insights on Consumers
in UK&I (United Kingdom & Ireland). This particular subsystem on the
Mainframe comprised approximately 7 million lines of code, developed over a
span of 40 years. It provided roughly ~50% of the capabilities of the UK&I
estate, but accounted for ~80% of MIPS (Million instructions per second)
from a runtime perspective. The system was significantly complex, the
complexity was further exacerbated by domain responsibilities and concerns
spread across multiple layers of the legacy environment.
Several reasons drove the client’s decision to transition away from the
Mainframe environment, these are the following:
- Changes to the system were slow and expensive. The business therefore had
challenges keeping pace with the rapidly evolving market, preventing
innovation. - Operational costs associated with running the Mainframe system were high;
the client faced a commercial risk with an imminent price increase from a core
software vendor. - Whilst our client had the necessary skill sets for running the Mainframe,
it had proven to be hard to find new professionals with expertise in this tech
stack, as the pool of skilled engineers in this domain is limited. Furthermore,
the job market does not offer as many opportunities for Mainframes, thus people
are not incentivised to learn how to develop and operate them.
High-level view of Consumer Subsystem
The following diagram shows, from a high-level perspective, the various
components and actors in the Consumer subsystem.
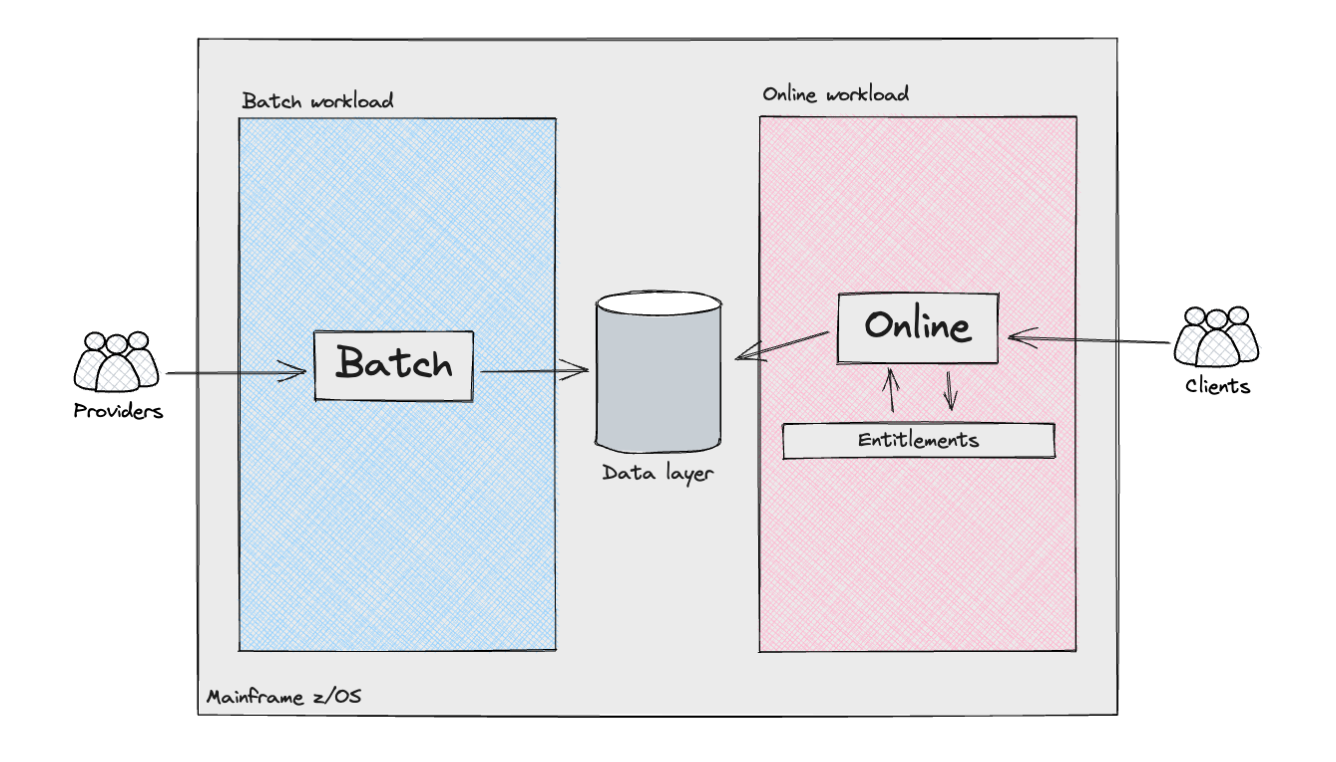
The Mainframe supported two distinct types of workloads: batch
processing and, for the product API layers, online transactions. The batch
workloads resembled what is commonly referred to as a data pipeline. They
involved the ingestion of semi-structured data from external
providers/sources, or other internal Mainframe systems, followed by data
cleansing and modelling to align with the requirements of the Consumer
Subsystem. These pipelines incorporated various complexities, including
the implementation of the Identity searching logic: in the United Kingdom,
unlike the United States with its social security number, there is no
universally unique identifier for residents. Consequently, companies
operating in the UK&I must employ customised algorithms to accurately
determine the individual identities associated with that data.
The online workload also presented significant complexities. The
orchestration of API requests was managed by multiple internally developed
frameworks, which determined the program execution flow by lookups in
datastores, alongside handling conditional branches by analysing the
output of the code. We should not overlook the level of customisation this
framework applied for each customer. For example, some flows were
orchestrated with ad-hoc configuration, catering for implementation
details or specific needs of the systems interacting with our client’s
online products. These configurations were exceptional at first, but they
likely became the norm over time, as our client augmented their online
offerings.
This was implemented through an Entitlements engine which operated
across layers to ensure that customers accessing products and underlying
data were authenticated and authorised to retrieve either raw or
aggregated data, which would then be exposed to them through an API
response.
Incremental Legacy Displacement: Principles, Benefits, and
Considerations
Considering the scope, risks, and complexity of the Consumer Subsystem,
we believed the following principles would be tightly linked with us
succeeding with the programme:
- Early Risk Reduction: With engineering starting from the
beginning, the implementation of a “Fail-Fast” approach would help us
identify potential pitfalls and uncertainties early, thus preventing
delays from a programme delivery standpoint. These were: - Outcome Parity: The client emphasised the importance of
upholding outcome parity between the existing legacy system and the
new system (It is important to note that this concept differs from
Feature Parity). In the client’s Legacy system, various
attributes were generated for each consumer, and given the strict
industry regulations, maintaining continuity was essential to ensure
contractual compliance. We needed to proactively identify
discrepancies in data early on, promptly address or explain them, and
establish trust and confidence with both our client and their
respective customers at an early stage. - Cross-functional requirements: The Mainframe is a highly
performant machine, and there were uncertainties that a solution on
the Cloud would satisfy the Cross-functional requirements. - Deliver Value Early: Collaboration with the client would
ensure we could identify a subset of the most critical Business
Capabilities we could deliver early, ensuring we could break the system
apart into smaller increments. These represented thin-slices of the
overall system. Our goal was to build upon these slices iteratively and
frequently, helping us accelerate our overall learning in the domain.
Furthermore, working through a thin-slice helps reduce the cognitive
load required from the team, thus preventing analysis paralysis and
ensuring value would be consistently delivered. To achieve this, a
platform built around the Mainframe that provides better control over
clients’ migration strategies plays a vital role. Using patterns such as
Dark Launching and Canary
Release would place us in the driver’s seat for a smooth
transition to the Cloud. Our goal was to achieve a silent migration
process, where customers would seamlessly transition between systems
without any noticeable impact. This could only be possible through
comprehensive comparison testing and continuous monitoring of outputs
from both systems.
With the above principles and requirements in mind, we opted for an
Incremental Legacy Displacement approach in conjunction with Dual
Run. Effectively, for each slice of the system we were rebuilding on the
Cloud, we were planning to feed both the new and as-is system with the
same inputs and run them in parallel. This allows us to extract both
systems’ outputs and check if they are the same, or at least within an
acceptable tolerance. In this context, we defined Incremental Dual
Run as: using a Transitional
Architecture to support slice-by-slice displacement of capability
away from a legacy environment, thereby enabling target and as-is systems
to run temporarily in parallel and deliver value.
We decided to adopt this architectural pattern to strike a balance
between delivering value, discovering and managing risks early on,
ensuring outcome parity, and maintaining a smooth transition for our
client throughout the duration of the programme.
Incremental Legacy Displacement approach
To accomplish the offloading of capabilities to our target
architecture, the team worked closely with Mainframe SMEs (Subject Matter
Experts) and our client’s engineers. This collaboration facilitated a
just enough understanding of the current as-is landscape, in terms of both
technical and business capabilities; it helped us design a Transitional
Architecture to connect the existing Mainframe to the Cloud-based system,
the latter being developed by other delivery workstreams in the
programme.
Our approach began with the decomposition of the
Consumer subsystem into specific business and technical domains, including
data load, data retrieval & aggregation, and the product layer
accessible through external-facing APIs.
Because of our client’s business
purpose, we recognised early that we could exploit a major technical boundary to organise our programme. The
client’s workload was largely analytical, processing mostly external data
to produce insight which was sold on to clients. We therefore saw an
opportunity to split our transformation programme in two parts, one around
data curation, the other around data serving and product use cases using
data interactions as a seam. This was the first high level seam identified.
Following that, we then needed to further break down the programme into
smaller increments.
On the data curation side, we identified that the data sets were
managed largely independently of each other; that is, while there were
upstream and downstream dependencies, there was no entanglement of the datasets during curation, i.e.
ingested data sets had a one to one mapping to their input files.
.
We then collaborated closely with SMEs to identify the seams
within the technical implementation (laid out below) to plan how we could
deliver a cloud migration for any given data set, eventually to the level
where they could be delivered in any order (Database Writers Processing Pipeline Seam, Coarse Seam: Batch Pipeline Step Handoff as Seam,
and Most Granular: Data Characteristic
Seam). As long as up- and downstream dependencies could exchange data
from the new cloud system, these workloads could be modernised
independently of each other.
On the serving and product side, we found that any given product used
80% of the capabilities and data sets that our client had created. We
needed to find a different approach. After investigation of the way access
was sold to customers, we found that we could take a “customer segment”
approach to deliver the work incrementally. This entailed finding an
initial subset of customers who had purchased a smaller percentage of the
capabilities and data, reducing the scope and time needed to deliver the
first increment. Subsequent increments would build on top of prior work,
enabling further customer segments to be cut over from the as-is to the
target architecture. This required using a different set of seams and
transitional architecture, which we discuss in Database Readers and Downstream processing as a Seam.
Effectively, we ran a thorough analysis of the components that, from a
business perspective, functioned as a cohesive whole but were built as
distinct elements that could be migrated independently to the Cloud and
laid this out as a programme of sequenced increments.
Seams
Our transitional architecture was mostly influenced by the Legacy seams we could uncover within the Mainframe. You
can think of them as the junction points where code, programs, or modules
meet. In a legacy system, they may have been intentionally designed at
strategic places for better modularity, extensibility, and
maintainability. If this is the case, they will likely stand out
throughout the code, although when a system has been under development for
a number of decades, these seams tend to hide themselves amongst the
complexity of the code. Seams are particularly valuable because they can
be employed strategically to alter the behaviour of applications, for
example to intercept data flows within the Mainframe allowing for
capabilities to be offloaded to a new system.
Determining technical seams and valuable delivery increments was a
symbiotic process; possibilities in the technical area fed the options
that we could use to plan increments, which in turn drove the transitional
architecture needed to support the programme. Here, we step a level lower
in technical detail to discuss solutions we planned and designed to enable
Incremental Legacy Displacement for our client. It is important to note that these were continuously refined
throughout our engagement as we acquired more knowledge; some went as far as being deployed to test
environments, whilst others were spikes. As we adopt this approach on other large-scale Mainframe modernisation
programmes, these approaches will be further refined with our most up to date hands-on experience.
External interfaces
We examined the external interfaces exposed by the Mainframe to data
Providers and our client’s Customers. We could apply Event Interception on these integration points
to allow the transition of external-facing workload to the cloud, so the
migration would be silent from their perspective. There were two types
of interfaces into the Mainframe: a file-based transfer for Providers to
supply data to our client, and a web-based set of APIs for Customers to
interact with the product layer.
Batch input as seam
The first external seam that we found was the file-transfer
service.
Providers could transfer files containing data in a semi-structured
format via two routes: a web-based GUI (Graphical User Interface) for
file uploads interacting with the underlying file transfer service, or
an FTP-based file transfer to the service directly for programmatic
access.
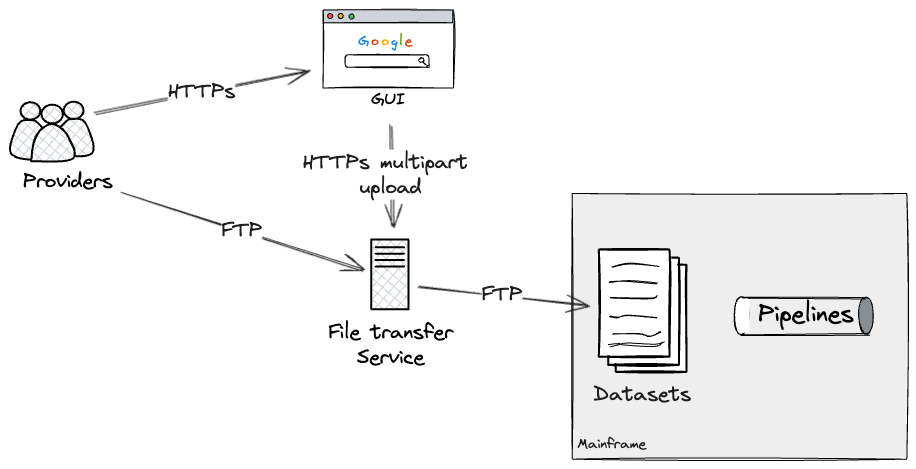
The file transfer service determined, on a per provider and file
basis, what datasets on the Mainframe should be updated. These would
in turn execute the relevant pipelines through dataset triggers, which
were configured on the batch job scheduler.
Assuming we could rebuild each pipeline as a whole on the Cloud
(note that later we will dive deeper into breaking down larger
pipelines into workable chunks), our approach was to build an
individual pipeline on the cloud, and dual run it with the mainframe
to verify they were producing the same outputs. In our case, this was
possible through applying additional configurations on the File
transfer service, which forked uploads to both Mainframe and Cloud. We
were able to test this approach using a production-like File transfer
service, but with dummy data, running on test environments.
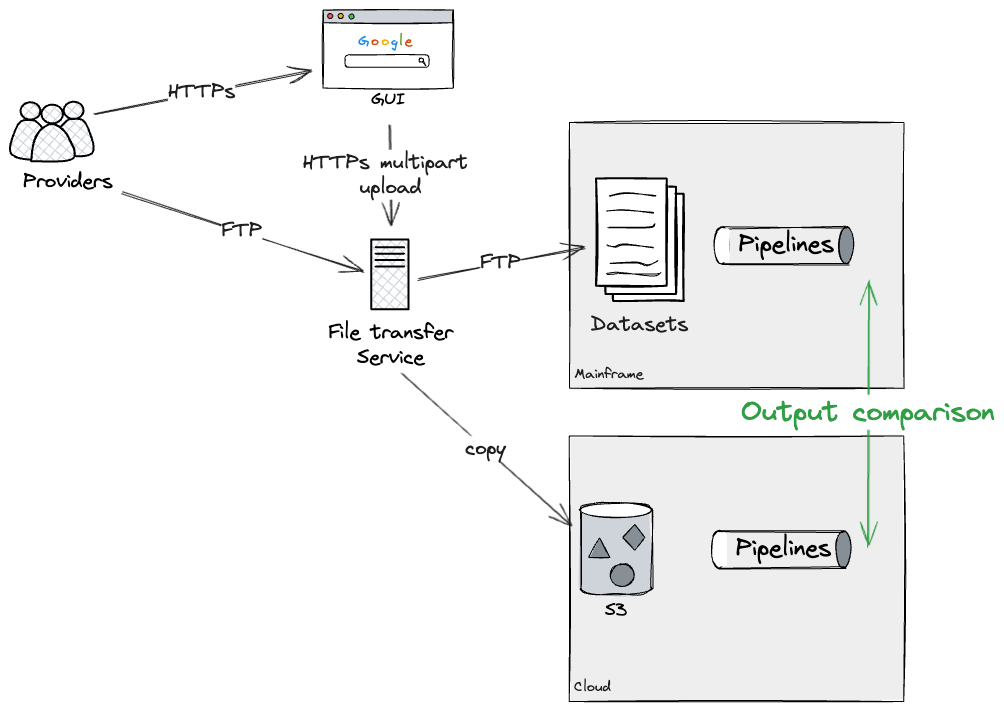
This would allow us to Dual Run each pipeline both on Cloud and
Mainframe, for as long as required, to gain confidence that there were
no discrepancies. Eventually, our approach would have been to apply an
additional configuration to the File transfer service, preventing
further updates to the Mainframe datasets, therefore leaving as-is
pipelines deprecated. We did not get to test this last step ourselves
as we did not complete the rebuild of a pipeline end to end, but our
technical SMEs were familiar with the configurations required on the
File transfer service to effectively deprecate a Mainframe
pipeline.
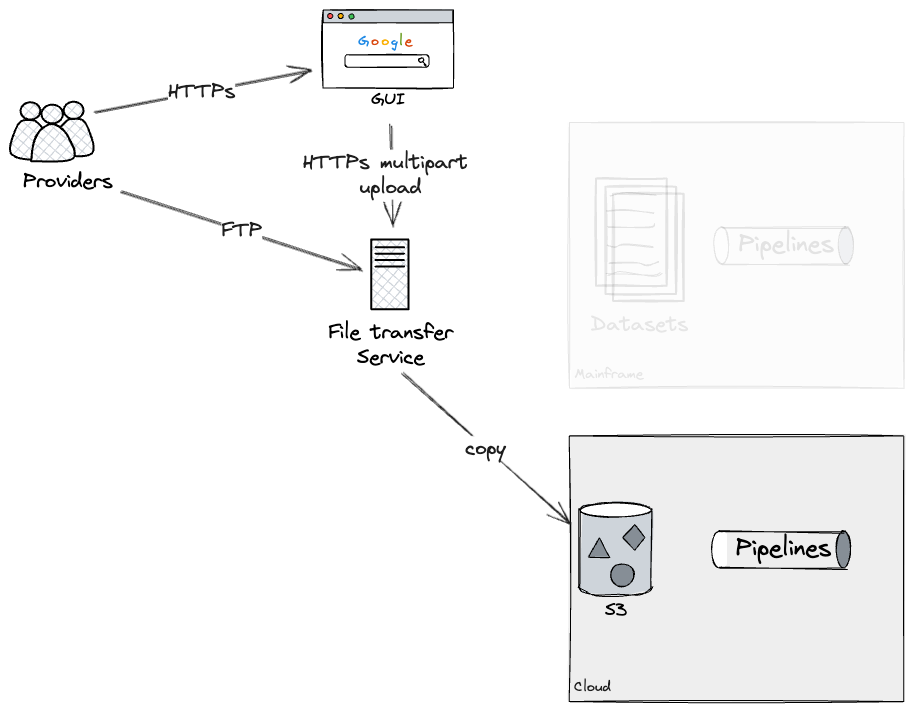
API Access as Seam
Furthermore, we adopted a similar strategy for the external facing
APIs, identifying a seam around the pre-existing API Gateway exposed
to Customers, representing their entrypoint to the Consumer
Subsystem.
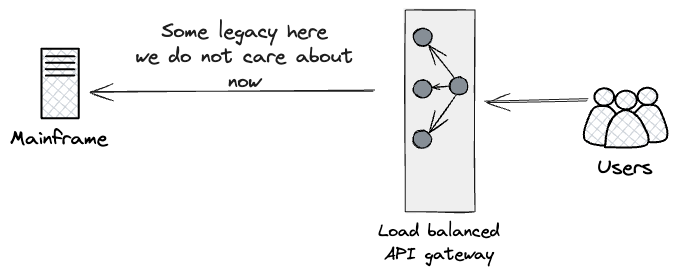
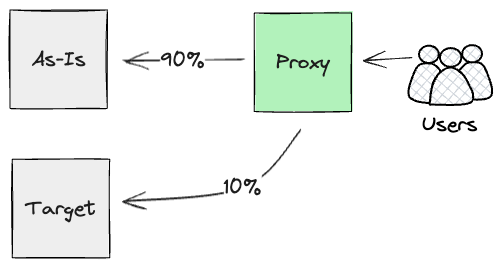
Drawing from Dual Run, the approach we designed would be to put a
proxy high up the chain of HTTPS calls, as close to users as possible.
We were looking for something that could parallel run both streams of
calls (the As-Is mainframe and newly built APIs on Cloud), and report
back on their outcomes.

Effectively, we were planning to use Dark
Launching for the new Product layer, to gain early confidence
in the artefact through extensive and continuous monitoring of their
outputs. We did not prioritise building this proxy in the first year;
to exploit its value, we needed to have the majority of functionality
rebuilt at the product level. However, our intentions were to build it
as soon as any meaningful comparison tests could be run at the API
layer, as this component would play a key role for orchestrating dark
launch comparison tests. Additionally, our analysis highlighted we
needed to watch out for any side-effects generated by the Products
layer. In our case, the Mainframe produced side effects, such as
billing events. As a result, we would have needed to make intrusive
Mainframe code changes to prevent duplication and ensure that
customers would not get billed twice.
Similarly to the Batch input seam, we could run these requests in
parallel for as long as it was required. Ultimately though, we would
use Canary
Release at the
proxy layer to cut over customer-by-customer to the Cloud, hence
reducing, incrementally, the workload executed on the Mainframe.
Internal interfaces
Following that, we conducted an analysis of the internal components
within the Mainframe to pinpoint the specific seams we could leverage to
migrate more granular capabilities to the Cloud.
Coarse Seam: Data interactions as a Seam
One of the primary areas of focus was the pervasive database
accesses across programs. Here, we started our analysis by identifying
the programs that were either writing, reading, or doing both with the
database. Treating the database itself as a seam allowed us to break
apart flows that relied on it being the connection between
programs.
Database Readers
Regarding Database readers, to enable new Data API development in
the Cloud environment, both the Mainframe and the Cloud system needed
access to the same data. We analysed the database tables accessed by
the product we picked as a first candidate for migrating the first
customer segment, and worked with client teams to deliver a data
replication solution. This replicated the required tables from the test database to the Cloud using Change
Data Capture (CDC) techniques to synchronise sources to targets. By
leveraging a CDC tool, we were able to replicate the required
subset of data in a near-real time fashion across target stores on
Cloud. Also, replicating data gave us opportunities to redesign its
model, as our client would now have access to stores that were not
only relational (e.g. Document stores, Events, Key-Value and Graphs
were considered). Criterias such as access patterns, query complexity,
and schema flexibility helped determine, for each subset of data, what
tech stack to replicate into. During the first year, we built
replication streams from DB2 to both Kafka and Postgres.
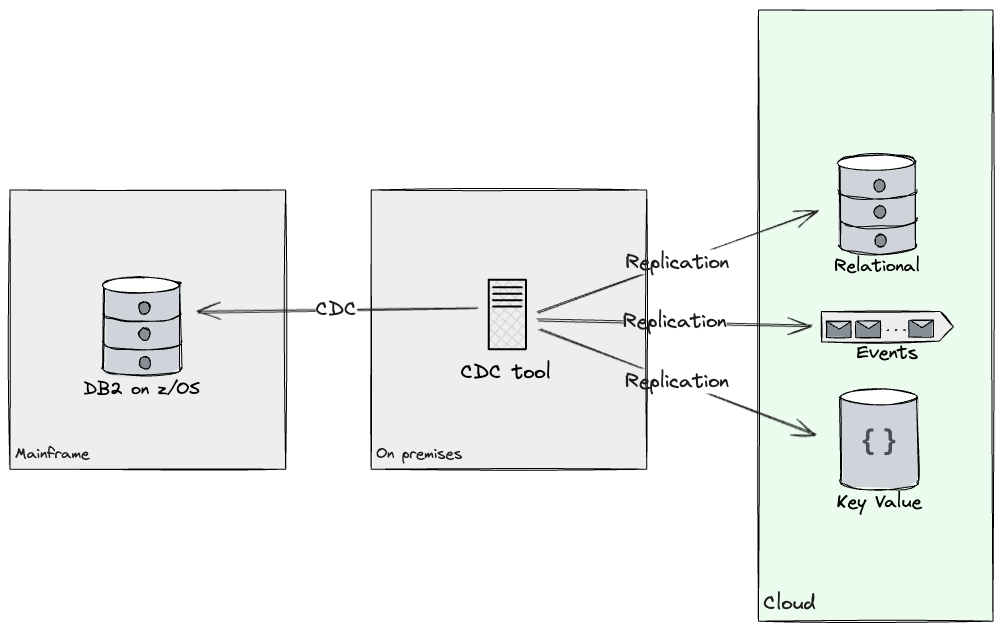
At this point, capabilities implemented through programs
reading from the database could be rebuilt and later migrated to
the Cloud, incrementally.
Database Writers
In regards to database writers, which were mostly made up of batch
workloads running on the Mainframe, after careful analysis of the data
flowing through and out of them, we were able to apply Extract Product Lines to identify
separate domains that could execute independently of each other
(running as part of the same flow was just an implementation detail we
could change).
Working with such atomic units, and around their respective seams,
allowed other workstreams to start rebuilding some of these pipelines
on the cloud and comparing the outputs with the Mainframe.

In addition to building the transitional architecture, our team was
responsible for providing a range of services that were used by other
workstreams to engineer their data pipelines and products. In this
specific case, we built batch jobs on Mainframe, executed
programmatically by dropping a file in the file transfer service, that
would extract and format the journals that those pipelines were
producing on the Mainframe, thus allowing our colleagues to have tight
feedback loops on their work through automated comparison testing.
After ensuring that outcomes remained the same, our approach for the
future would have been to enable other teams to cutover each
sub-pipeline one by one.
The artefacts produced by a sub-pipeline may be required on the
Mainframe for further processing (e.g. Online transactions). Thus, the
approach we opted for, when these pipelines would later be complete
and on the Cloud, was to use Legacy Mimic
and replicate data back to the Mainframe, for as long as the capability dependant on this data would be
moved to Cloud too. To achieve this, we were considering employing the same CDC tool for replication to the
Cloud. In this scenario, records processed on Cloud would be stored as events on a stream. Having the
Mainframe consume this stream directly seemed complex, both to build and to test the system for regressions,
and it demanded a more invasive approach on the legacy code. In order to mitigate this risk, we designed an
adaption layer that would transform the data back into the format the Mainframe could work with, as if that
data had been produced by the Mainframe itself. These transformation functions, if
straightforward, may be supported by your chosen replication tool, but
in our case we assumed we needed custom software to be built alongside
the replication tool to cater for additional requirements from the
Cloud. This is a common scenario we see in which businesses take the
opportunity, coming from rebuilding existing processing from scratch,
to improve them (e.g. by making them more efficient).
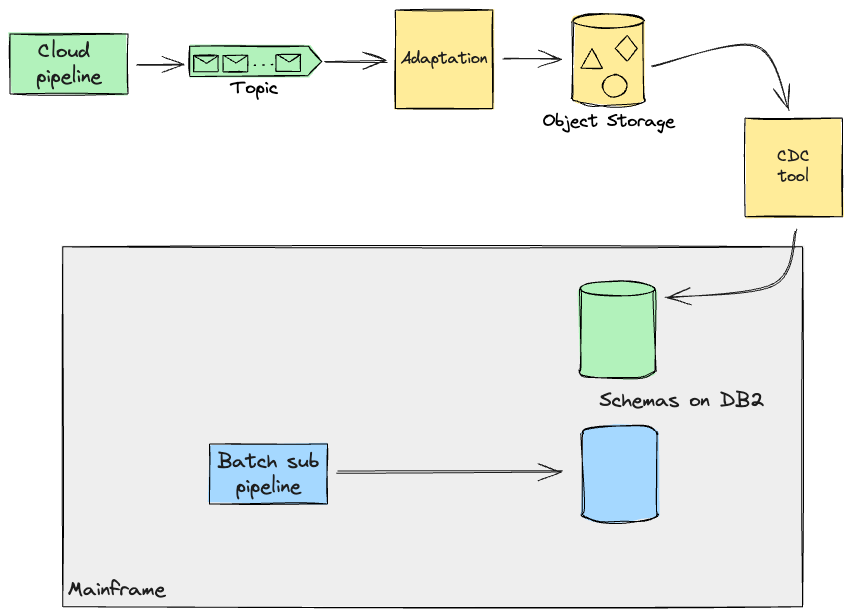
In summary, working closely with SMEs from the client-side helped
us challenge the existing implementation of Batch workloads on the
Mainframe, and work out alternative discrete pipelines with clearer
data boundaries. Note that the pipelines we were dealing with did not
overlap on the same records, due to the boundaries we had defined with
the SMEs. In a later section, we will examine more complex cases that
we have had to deal with.
Coarse Seam: Batch Pipeline Step Handoff
Likely, the database won’t be the only seam you can work with. In
our case, we had data pipelines that, in addition to persisting their
outputs on the database, were serving curated data to downstream
pipelines for further processing.
For these scenarios, we first identified the handshakes between
pipelines. These consist usually of state persisted in flat / VSAM
(Virtual Storage Access Method) files, or potentially TSQs (Temporary
Storage Queues). The following shows these hand-offs between pipeline
steps.

As an example, we were looking at designs for migrating a downstream pipeline reading a curated flat file
stored upstream. This downstream pipeline on the Mainframe produced a VSAM file that would be queried by
online transactions. As we were planning to build this event-driven pipeline on the Cloud, we chose to
leverage the CDC tool to get this data off the mainframe, which in turn would get converted into a stream of
events for the Cloud data pipelines to consume. Similarly to what we have reported before, our Transitional
Architecture needed to use an Adaptation layer (e.g. Schema translation) and the CDC tool to copy the
artefacts produced on Cloud back to the Mainframe.
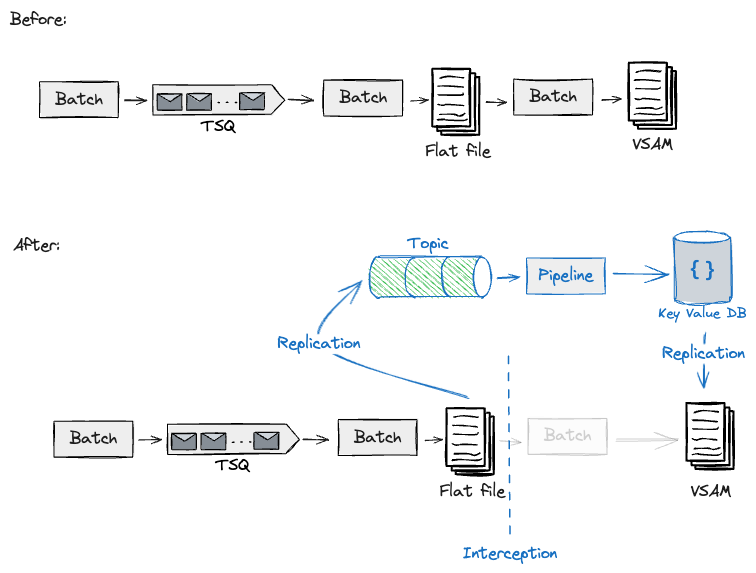
Through employing these handshakes that we had previously
identified, we were able to build and test this interception for one
exemplary pipeline, and design further migrations of
upstream/downstream pipelines on the Cloud with the same approach,
using Legacy
Mimic
to feed back the Mainframe with the necessary data to proceed with
downstream processing. Adjacent to these handshakes, we were making
non-trivial changes to the Mainframe to allow data to be extracted and
fed back. However, we were still minimising risks by reusing the same
batch workloads at the core with different job triggers at the edges.
Granular Seam: Data Characteristic
In some cases the above approaches for internal seam findings and
transition strategies do not suffice, as it happened with our project
due to the size of the workload that we were looking to cutover, thus
translating into higher risks for the business. In one of our
scenarios, we were working with a discrete module feeding off the data
load pipelines: Identity curation.
Consumer Identity curation was a
complex space, and in our case it was a differentiator for our client;
thus, they could not afford to have an outcome from the new system
less accurate than the Mainframe for the UK&I population. To
successfully migrate the entire module to the Cloud, we would need to
build tens of identity search rules and their required database
operations. Therefore, we needed to break this down further to keep
changes small, and enable delivering frequently to keep risks low.
We worked closely with the SMEs and Engineering teams with the aim
to identify characteristics in the data and rules, and use them as
seams, that would allow us to incrementally cutover this module to the
Cloud. Upon analysis, we categorised these rules into two distinct
groups: Simple and Complex.
Simple rules could run on both systems, provided
they fed on different data segments (i.e. separate pipelines
upstream), thus they represented an opportunity to further break apart
the identity module space. They represented the majority (circa 70%)
triggered during the ingestion of a file. These rules were responsible
for establishing an association between an already existing identity,
and a new data record.
On the other hand, the Complex rules were triggered by cases where
a data record indicated the need for an identity change, such as
creation, deletion, or updation. These rules required careful handling
and could not be migrated incrementally. This is because an update to
an identity can be triggered by multiple data segments, and operating
these rules in both systems in parallel could lead to identity drift
and data quality loss. They required a single system minting
identities at one point in time, thus we designed for a big bang
migration approach.
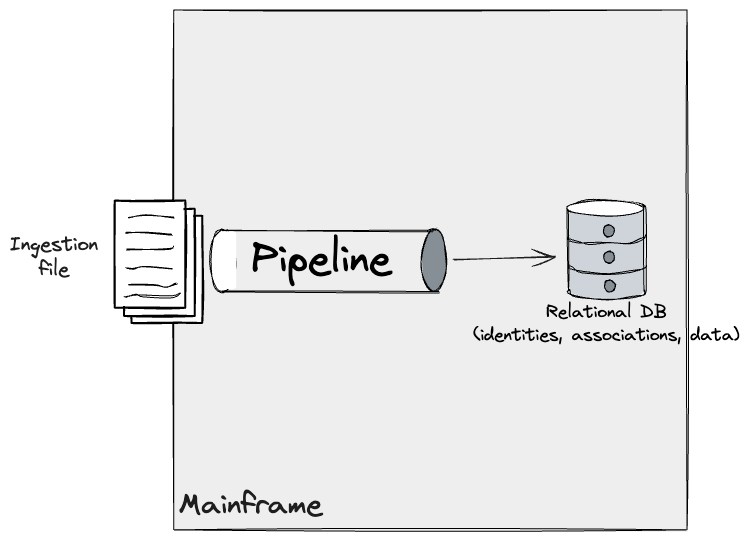
In our original understanding of the Identity module on the
Mainframe, pipelines ingesting data triggered changes on DB2 resulting
in an up to date view of the identities, data records, and their
associations.
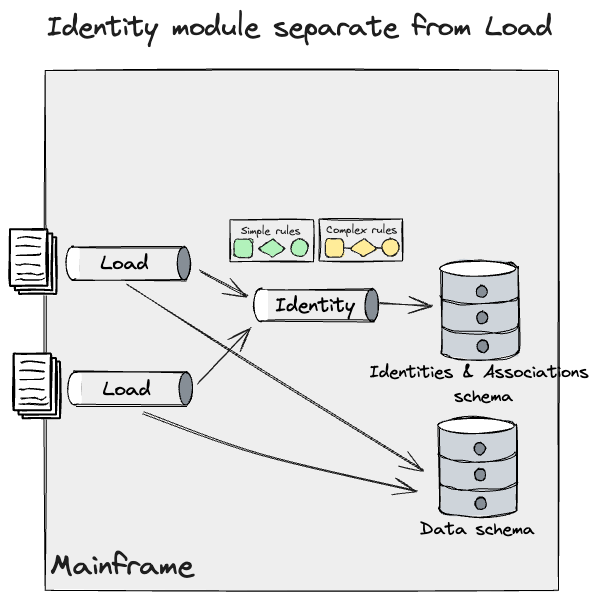
Additionally, we identified a discrete Identity module and refined
this model to reflect a deeper understanding of the system that we had
discovered with the SMEs. This module fed data from multiple data
pipelines, and applied Simple and Complex rules to DB2.
Now, we could apply the same techniques we wrote about earlier for
data pipelines, but we required a more granular and incremental
approach for the Identity one.
We planned to tackle the Simple rules that could run on both
systems, with a caveat that they operated on different data segments,
as we were constrained to having only one system maintaining identity
data. We worked on a design that used Batch Pipeline Step Handoff and
applied Event Interception to capture and fork the data (temporarily
until we can confirm that no data is lost between system handoffs)
feeding the Identity pipeline on the Mainframe. This would allow us to
take a divide and conquer approach with the files ingested, running a
parallel workload on the Cloud which would execute the Simple rules
and apply changes to identities on the Mainframe, and build it
incrementally. There were many rules that fell under the Simple
bucket, therefore we needed a capability on the target Identity module
to fall back to the Mainframe in case a rule which was not yet
implemented needed to be triggered. This looked like the
following:
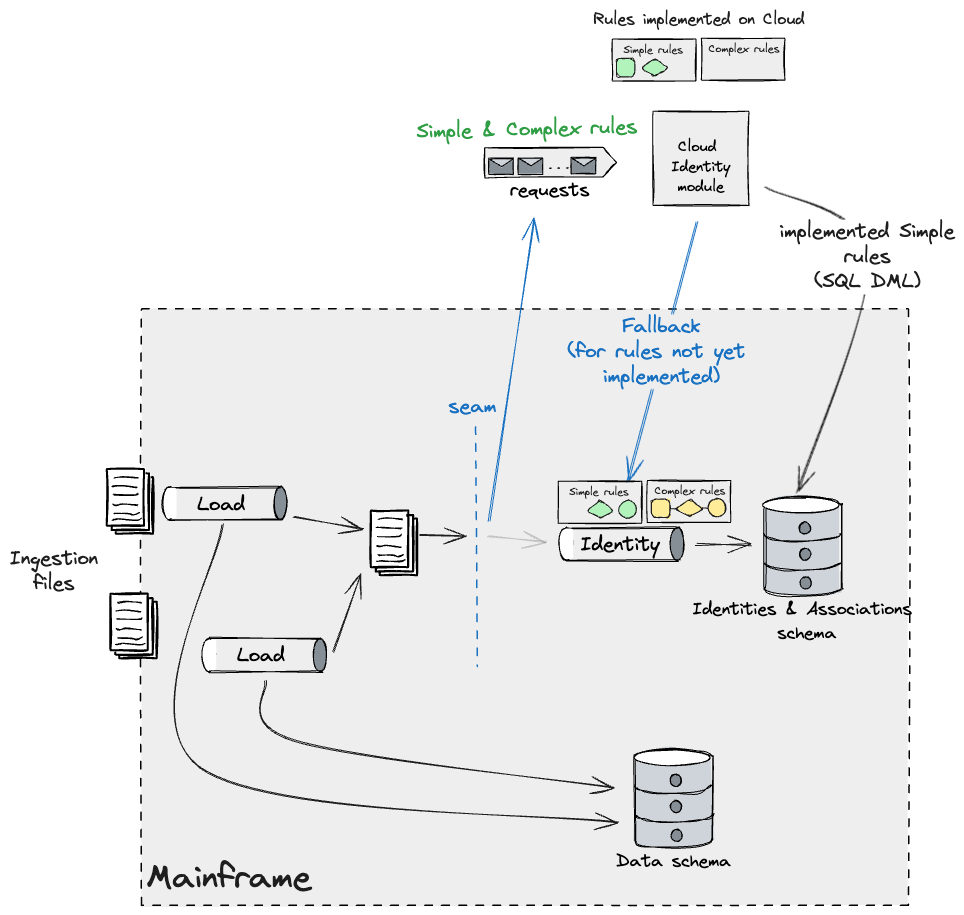
As new builds of the Cloud Identity module get released, we would
see less rules belonging to the Simple bucket being applied through
the fallback mechanism. Eventually only the Complex ones will be
observable through that leg. As we previously mentioned, these needed
to be migrated all in one go to minimise the impact of identity drift.
Our plan was to build Complex rules incrementally against a Cloud
database replica and validate their outcomes through extensive
comparison testing.
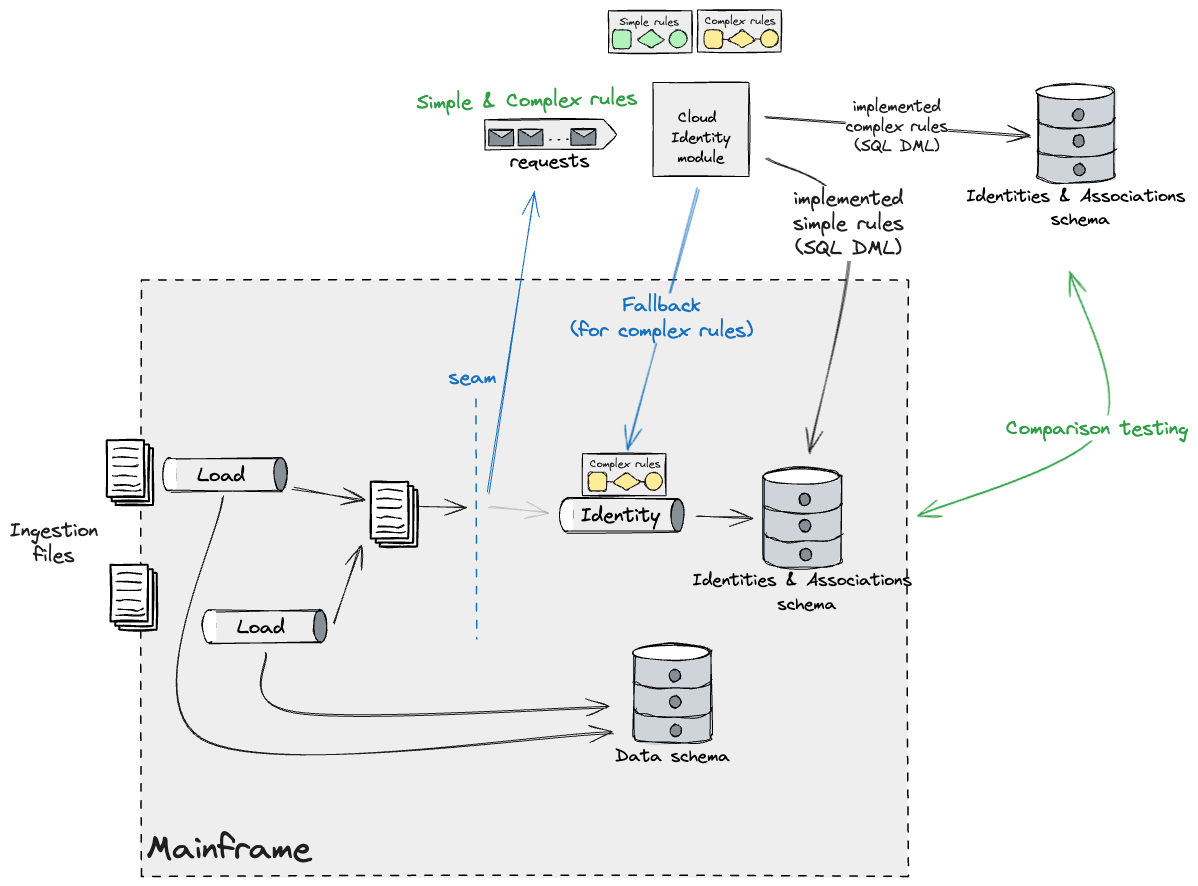
Once all rules were built, we would release this code and disable
the fallback strategy to the Mainframe. Bear in mind that upon
releasing this, the Mainframe Identities and Associations data becomes
effectively a replica of the new Primary store managed by the Cloud
Identity module. Therefore, replication is needed to keep the
mainframe functioning as is.
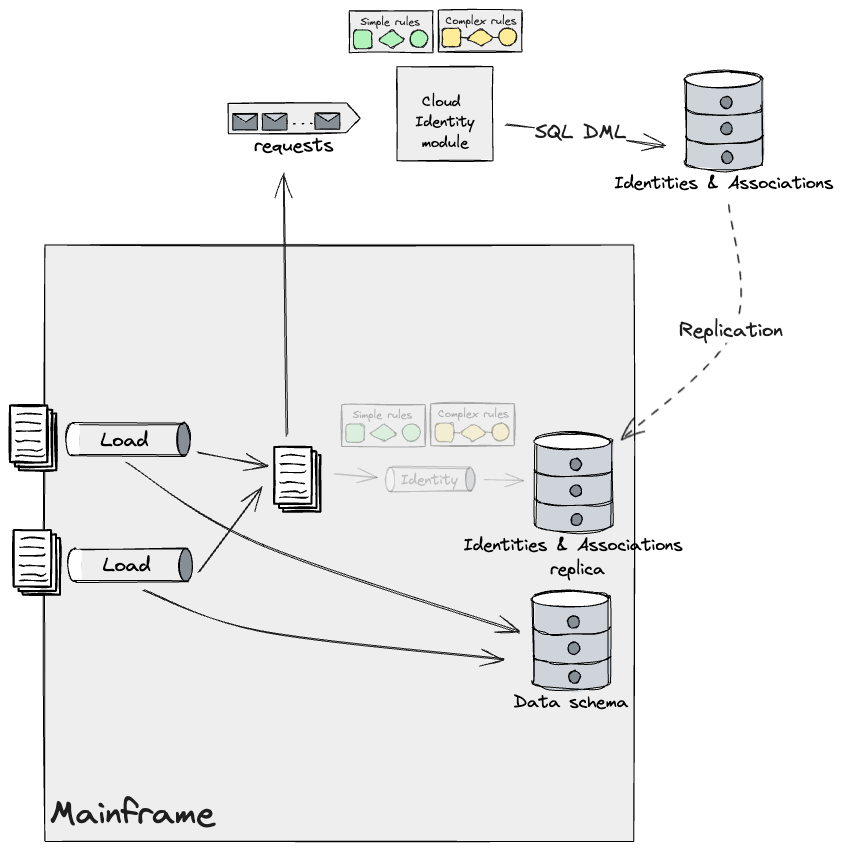
As previously mentioned in other sections, our design employed
Legacy Mimic and an Anti-Corruption Layer that would translate data
from the Mainframe to the Cloud model and vice versa. This layer
consisted of a series of Adapters across the systems, ensuring data
would flow out as a stream from the Mainframe for the Cloud to consume
using event-driven data pipelines, and as flat files back to the
Mainframe to allow existing Batch jobs to process them. For
simplicity, the diagrams above don’t show these adapters, but they
would be implemented each time data flowed across systems, regardless
of how granular the seam was. Unfortunately, our work here was mostly
analysis and design and we were not able to take it to the next step
and validate our assumptions end to end, apart from running Spikes to
ensure that a CDC tool and the File transfer service could be
employed to send data in and out of the Mainframe, in the required
format. The time required to build the required scaffolding around the
Mainframe, and reverse engineer the as-is pipelines to gather the
requirements was considerable and beyond the timeframe of the first
phase of the programme.
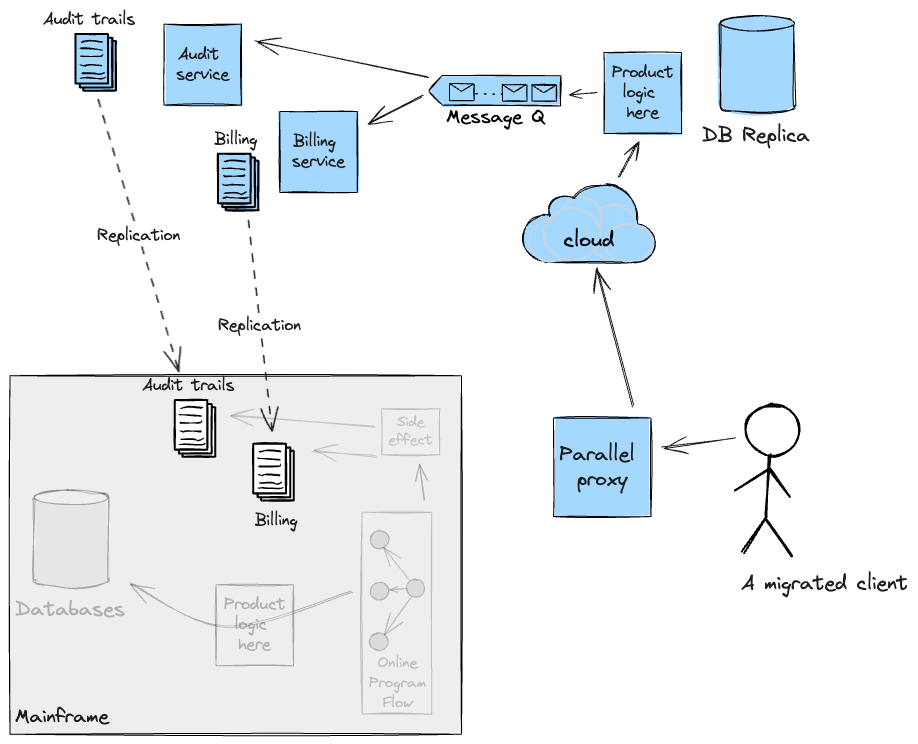
Granular Seam: Downstream processing handoff
Similar to the approach employed for upstream pipelines to feed
downstream batch workloads, Legacy Mimic Adapters were employed for
the migration of the Online flow. In the existing system, a customer
API call triggers a series of programs producing side-effects, such as
billing and audit trails, which get persisted in appropriate
datastores (mostly Journals) on the Mainframe.
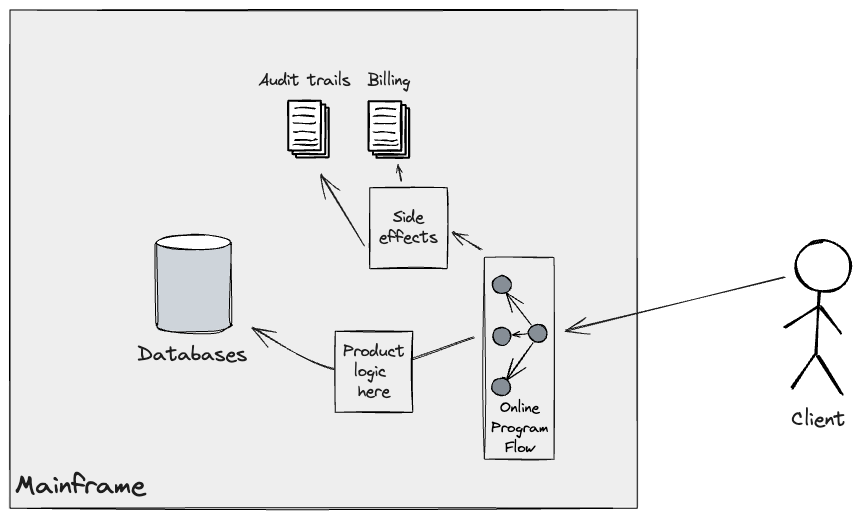
To successfully transition incrementally the online flow to the
Cloud, we needed to ensure these side-effects would either be handled
by the new system directly, thus increasing scope on the Cloud, or
provide adapters back to the Mainframe to execute and orchestrate the
underlying program flows responsible for them. In our case, we opted
for the latter using CICS web services. The solution we built was
tested for functional requirements; cross-functional ones (such as
Latency and Performance) could not be validated as it proved
challenging to get production-like Mainframe test environments in the
first phase. The following diagram shows, according to the
implementation of our Adapter, what the flow for a migrated customer
would look like.
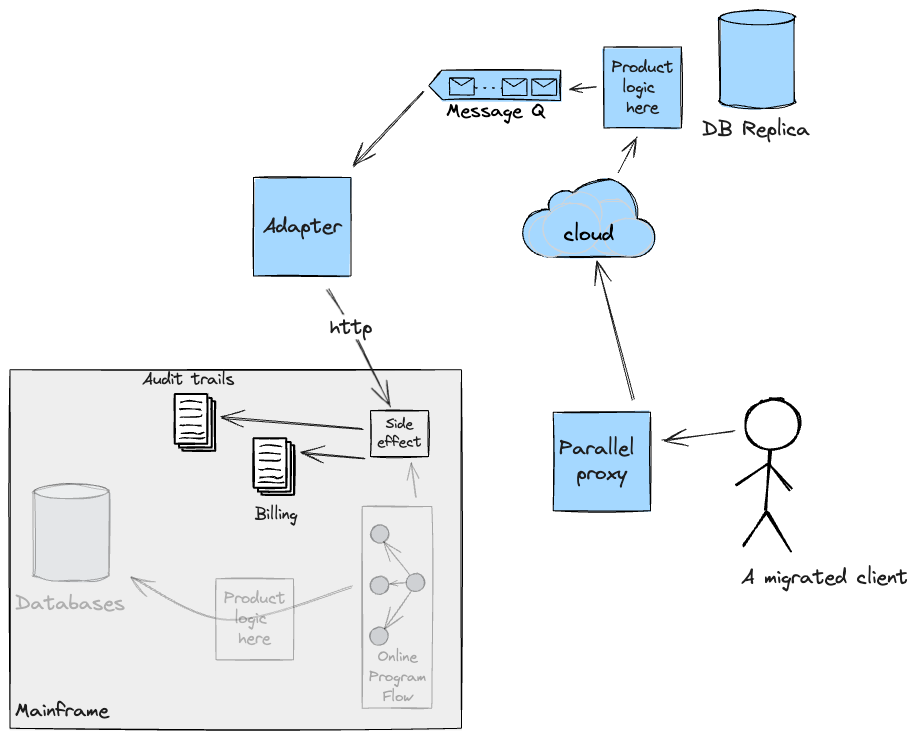
It is worth noting that Adapters were planned to be temporary
scaffolding. They would not have served a valid purpose when the Cloud
was able to handle these side-effects by itself after which point we
planned to replicate the data back to the Mainframe for as long as
required for continuity.

{kind=link}