Generative AI and particularly LLMs (Large Language Models) have exploded
into the public consciousness. Like many software developers I am intrigued
by the possibilities, but unsure what exactly it will mean for our profession
in the long run. I have now taken on a role in Thoughtworks to coordinate our
work on how this technology will affect software delivery practices.
I’ll be posting various memos here to describe what my colleagues and I are
learning and thinking.
Latest Memo: The role of developer skills in agentic coding
25 March 2025
As agentic coding assistants become more capable, reactions vary widely. Some extrapolate from recent advancements and claim, “In a year, we won’t need developers anymore.” Others raise concerns about the quality of AI-generated code and the challenges of preparing junior developers for this changing landscape.
In the past few months, I have regularly used the agentic modes in Cursor, Windsurf and Cline, almost exclusively for changing existing codebases (as opposed to creating Tic Tac Toe from scratch). I am overall very impressed by the recent progress in IDE integration and how those integrations massively boost the way in which the tools can assist me. They
- execute tests and other development tasks, and try to immediately fix the errors that occur
- automatically pick up on and try to fix linting and compile errors
- can do web research
- some even have browser preview integration, to pick up on console errors or check DOM elements
All of this has led to impressive collaboration sessions with AI, and sometimes helps me build features and figure out problems in record time.
However.
Even in those successful sessions, I intervened, corrected and steered all the time. And often I decided to not even commit the changes. In this memo, I will list concrete examples of that steering, to illustrate what role the experience and skills of a developer play in this “supervised agent” mode. These examples show that while the advancements have been impressive, we’re still far away from AI writing code autonomously for non-trivial tasks. They also give ideas of the types of skills that developers will still have to apply for the foreseeable future. Those are the skills we have to preserve and train for.
Where I’ve had to steer
I want to preface this by saying that AI tools are categorically and always bad at the things that I’m listing. Some of the examples can even be easily mitigated with additional prompting or custom rules. Mitigated, but not fully controlled: LLMs frequently don’t listen to the letter of the prompt. The longer a coding session gets, the more hit-and-miss it becomes. So the things I’m listing absolutely have a non-negligible probability of happening, regardless of the rigor in prompting, or the number of context providers integrated into the coding assistant.
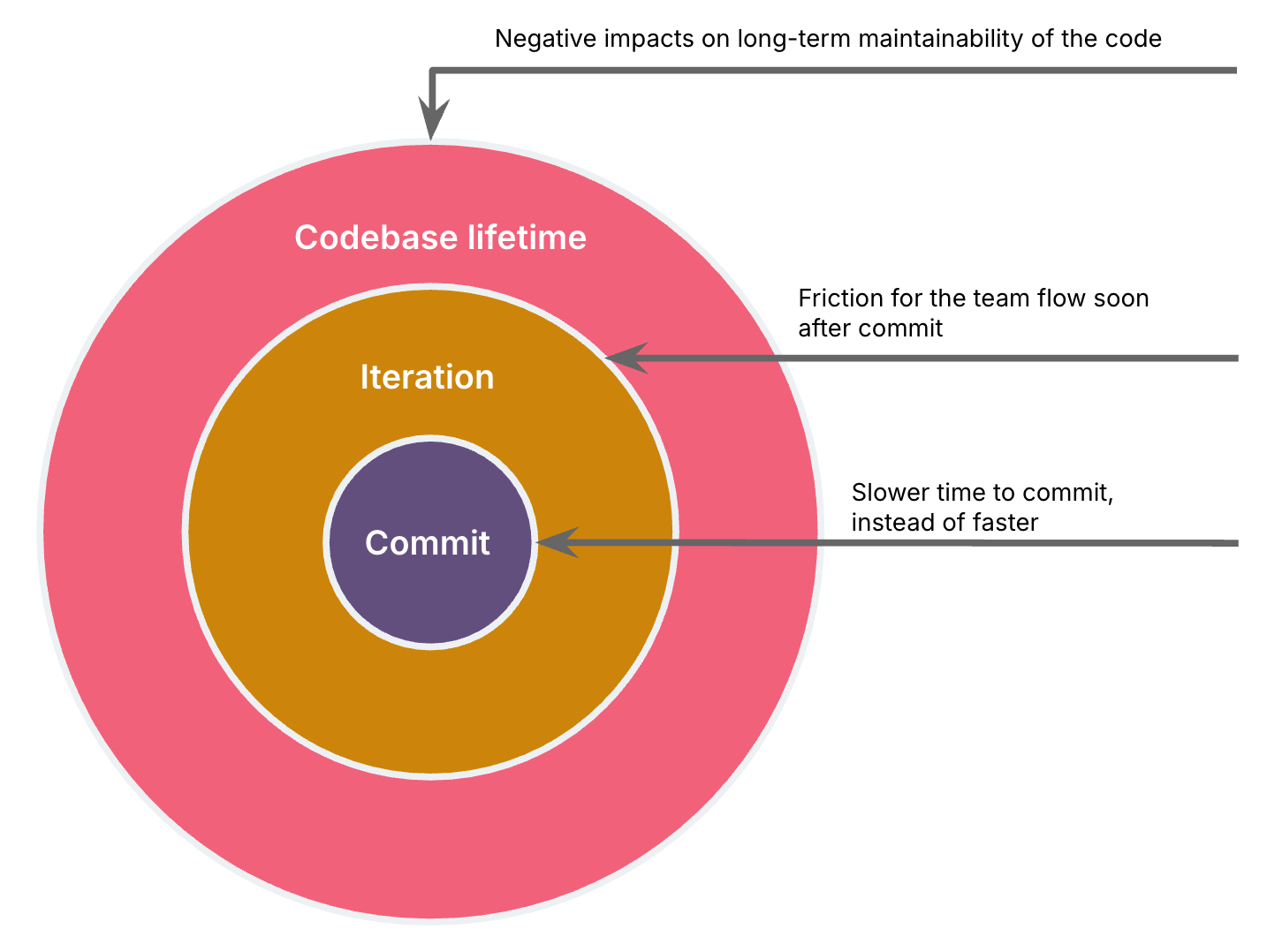
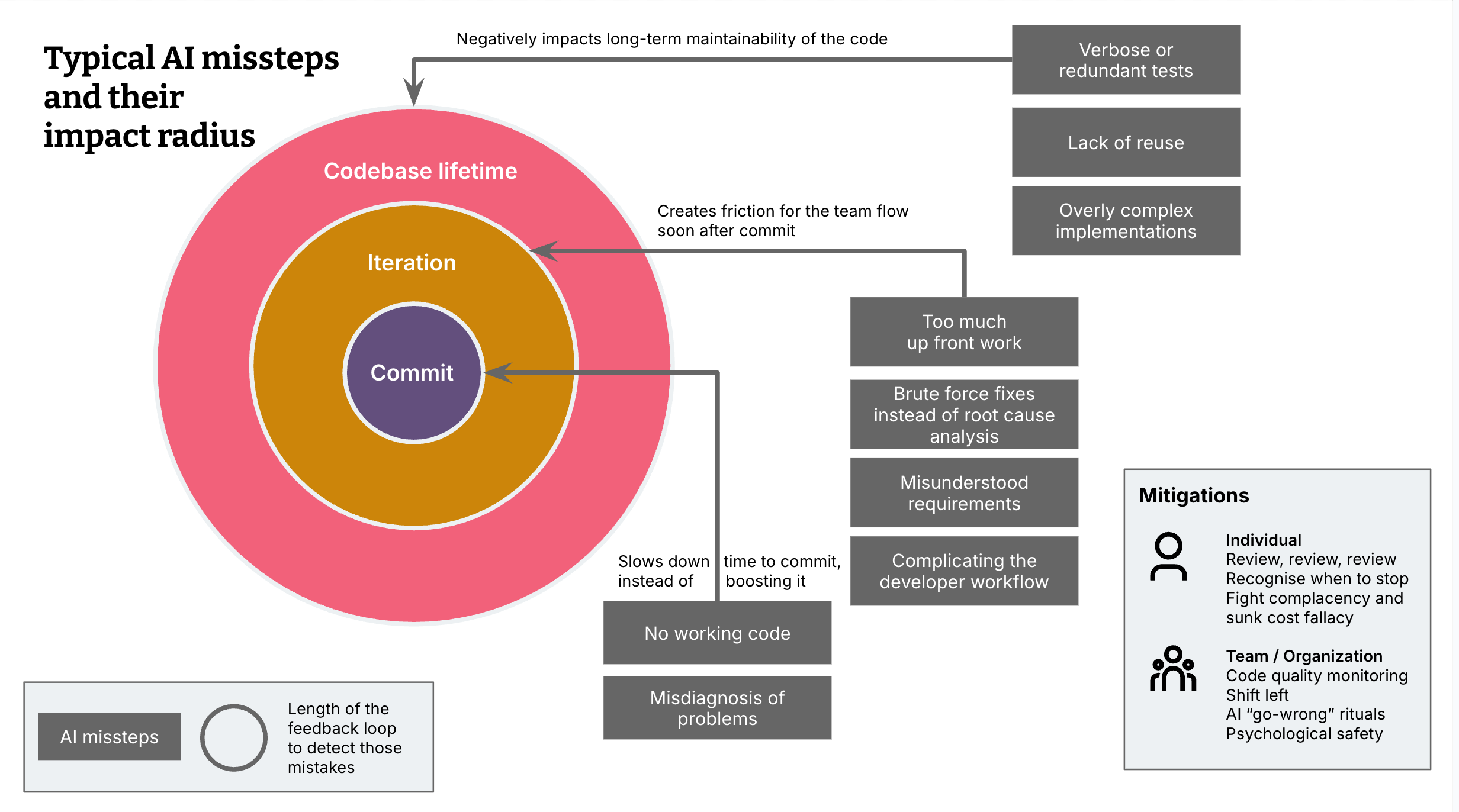
I am categorising my examples into 3 types of impact radius, AI missteps that:
a. slowed down my speed of development and time to commit instead of speeding it up (compared to unassisted coding), or
b. create friction for the team flow in that iteration, or
c. negatively impact long-term maintainability of the code.
The bigger the impact radius, the longer the feedback loop for a team to catch those issues.
Impact radius: Time to commit
These are the cases where AI hindered me more than it helped. This is actually the least problematic impact radius, because it’s the most obvious failure mode, and the changes most probably will not even make it into a commit.
No working code
At times my intervention was necessary to make the code work, plain and simple. So my experience either came into play because I could quickly correct where it went wrong, or because I knew early when to give up, and either start a new session with AI or work on the problem myself.
Misdiagnosis of problems
AI goes down rabbit holes quite frequently when it misdiagnoses a problem. Many of those times I can pull the tool back from the edge of those rabbit holes based on my previous experience with those problems.
Example: It assumed a Docker build issue was due to architecture settings for that Docker build and changed those settings based on that assumption — when in reality, the issue stemmed from copying node_modules built for the wrong architecture. As that is a typical problem I have come across many times, I could quickly catch it and redirect.
Impact radius: Team flow in the iteration
This category is about cases where a lack of review and intervention leads to friction on the team during that delivery iteration. My experience of working on many delivery teams helps me correct these before committing, as I have run into these second order effects many times. I imagine that even with AI, new developers will learn this by falling into these pitfalls and learning from them, the same way I did. The question is if the increased coding throughput with AI exacerbates this to a point where a team cannot absorb this sustainably.
Too much up-front work
AI often goes broad instead of incrementally implementing working slices of functionality. This risks wasting large upfront work before realizing a technology choice isn’t viable, or a functional requirement was misunderstood.
Example: During a frontend tech stack migration task, it tried converting all UI components at once rather than starting with one component and a vertical slice that integrates with the backend.
Brute-force fixes instead of root cause analysis
AI sometimes took brute-force approaches to solve issues rather than diagnosing what actually caused them. This delays the underlying problem to a later stage, and to other team members who then have to analyse without the context of the original change.
Example: When encountering a memory error during a Docker build, it increased the memory settings rather than questioning why so much memory was used in the first place.
Complicating the developer workflow
In one case, AI generated build workflows that create a bad developer experience. Pushing these changes almost immediately would have an impact on other team members’ development workflows.
Example: Introducing two commands to run an application’s frontend and backend, instead of one.
Example: Failing to ensure hot reload works.
Example: Complicated build setups that confused both me and the AI itself.
Example: Handling errors in Docker builds without considering how these errors could be caught earlier in the build process.
Misunderstood or incomplete requirements
Sometimes when I don’t give a detailed description of the functional requirements, AI jumps to the wrong conclusions. Catching this and redirecting the agent doesn’t necessarily need special development experience, just attention. However, it happened to me frequently, and is an example of how fully autonomous agents can fail when they don’t have a developer watching them work and intervening at the beginning, rather than at the end. In either case, be it the developer who doesn’t think along, or an agent who is fully autonomous, this misunderstanding will be caught later in the story lifecycle, and it will cause a bunch of back and forth to correct the work.
Impact radius: Long-term maintainability
This is the most insidious impact radius because it has the longest feedback loop, these issues might only be caught weeks and months later. These are the types of cases where the code will work fine for now, but will be harder to change in the future. Unfortunately, it’s also the category where my 20+ years of programming experience mattered the most.
Verbose and redundant tests
While AI can be fantastic at generating tests, I frequently find that it creates new test functions instead of adding assertions to existing ones, or that it adds too many assertions, i.e. some that were already covered in other tests. Counterintuitively for less experienced programmers, more tests are not necessarily better. The more tests and assertions get duplicated, the harder they are to maintain, and the more brittle the tests get. This can lead to a state where whenever a developer changes part of the code, multiple tests fail, leading to more overhead and frustration. I have tried to mitigate this behaviour with custom instructions, but it still happens frequently.
Lack of reuse
AI-generated code sometimes lacks modularity, making it difficult to apply the same approach elsewhere in the application.
Example: Not realising that a UI component is already implemented elsewhere, and therefore creating duplicate code.
Example: Use of inline CSS styles instead of CSS classes and variables
Overly complex or verbose code
Sometimes AI generates too much code, requiring me to remove unnecessary elements manually. This can either be code that is technically unnecessary and makes the code more complex, which will lead to problems when changing the code in the future. Or it can be more functionality than I actually need at that moment, which can increase maintenance cost for unnecessary lines of code.
Example: Every time AI does CSS changes for me, I then go and remove sometimes massive amounts of redundant CSS styles, one by one.
Example: AI generated a new web component that could dynamically display data inside of a JSON object, and it built a very elaborate version that was not needed at that point in time.
Example: During refactoring, it failed to recognize the existing dependency injection chain and introduced unnecessary additional parameters, making the design more brittle and harder to understand. E.g., it introduced a new parameter to a service constructor that was unnecessary, because the dependency that provided the value was already injected. (value = service_a.get_value(); ServiceB(service_a, value=value))
Conclusions
These experiences mean that by no stretch of my personal imagination will we have AI that writes 90% of our code autonomously in a year. Will it assist in writing 90% of the code? Maybe. For some teams, and some codebases. It assists me in 80% of the cases today (in a moderately complex, relatively small 15K LOC codebase).
What can you do to safeguard against AI missteps?
So how do you safeguard your software and team against the capriciousness of LLM-backed tools, to take advantage of the benefits of AI coding assistants?
Individual coder
-
Always carefully review AI-generated code. It’s very rare that I do NOT find something to fix or improve.
-
Stop AI coding sessions when you feel overwhelmed by what’s going on. Either revise your prompt and start a new session, or fall back to manual implementation – “artisanal coding”, as my colleague Steve Upton calls it.
-
Stay cautious of “good enough” solutions that were miraculously created in a very short amount of time, but introduce long-term maintenance costs.
-
Practice pair programming. Four eyes catch more than two, and two brains are less complacent than one
Team and organization
-
Good ol’ code quality monitoring. If you don’t have them already, set up tools like Sonarqube or Codescene to alert you about code smells. While they can’t catch everything, it’s a good building block of your safety net. Some code smells become more prominent with AI tools and should be more closely monitored than before, e.g. code duplication.
-
Pre-commit hooks and IDE-integrated code review. Remember to shift-left as much as possible – there are many tools that review, lint and security-check your code during a pull request, or in the pipeline. But the more you can catch directly during development, the better.
-
Revisit good code quality practices. In light of the types of the pitfalls described here, and other pitfalls a team experiences, create rituals that reiterate practices to mitigate the outer two impact radiuses. For example, you could keep a “Go-wrong” log of events where AI-generated code led to friction on the team, or affected maintainability, and reflect on them once a week.
-
Make use of custom rules. Most coding assistants now support the configuration of rule sets or instructions that will be sent along with every prompt. You can make use of those as a team to iterate on a baseline of prompt instructions to codify your good practices and mitigate some of the missteps listed here. However, as mentioned at the beginning, it is by no means guaranteed that the AI will follow them. The larger a session and therefore a context window gets, the more hit and miss it becomes.
-
A culture of trust and open communication. We are in a transition phase where this technology is seriously disrupting our ways of working, and everybody is a beginner and learner. Teams and organizations with a trustful culture and open communication are better equipped to learn and deal with the vulnerability this creates. For example, an organization that puts high pressure on their teams to deliver faster “because you now have AI” is more exposed to the quality risks mentioned here, because developers might cut corners to fulfill the expectations. And developers on teams with high trust and psychological safety will find it easier to share their challenges with AI adoption, and help the team learn faster to get the most out of the tools.
Thanks to Jim Gumbley, Karl Brown, Jörn Dinkla, Matteo Vaccari and Sarah Taraporewalla for their feedback and input.

{kind=link}