While I’ve put React application, there isn’t such a thing as React application. I mean, there are
front-end applications written in JavaScript or TypeScript that happen to
use React as their views. However, I think it’s not fair to call them React
applications, just as we wouldn’t call a Java EE application JSP
application.
More often than not, people squeeze different things into React
components or hooks to make the application work. This type of
less-organised structure isn’t a problem if the application is small or
mostly without much business logic. However, as more business logic shifted
to front-end in many cases, this everything-in-component shows problems. To
be more specific, the effort of understanding such type of code is
relatively high, as well as the increased risk to code modification.
In this article, I would like to discuss a few patterns and techniques
you can use to reshape your “React application” into a regular one, and only
with React as its view (you can even swap these views into another view
libray without too much efforts).
The critical point here is you should analyse what role each part of the
code is playing within an application (even on the surface, they might be
packed in the same file). Separate view from no-view logic, split the
no-view logic further by their responsibilities and place them in the
right places.
The benefit of this separation is that it allows you to make changes in
the underlying domain logic without worrying too much about the surface
views, or vice versa. Also, it can increase the reusability of the domain
logic in other places as they are not coupled to any other parts.
React is a humble library for building views
It’s easy to forget that React, at its core, is a library (not a
framework) that helps you build the user interface.
In this context, it is emphasized that React is a JavaScript library
that concentrates on a particular aspect of web development, namely UI
components, and offers ample freedom in terms of the design of the
application and its overall structure.
A JavaScript library for building user interfaces
It may sound pretty straightforward. But I have seen many cases where
people write the data fetching, reshaping logic right in the place where
it’s consumed. For example, fetching data inside a React component, in the
useEffect block right above the rendering, or performing data
mapping/transforming once they got the response from the server side.
useEffect(() => {
fetch("https://address.service/api")
.then((res) => res.json())
.then((data) => {
const addresses = data.map((item) => ({
street: item.streetName,
address: item.streetAddress,
postcode: item.postCode,
}));
setAddresses(addresses);
});
});
// the actual rendering...
Perhaps because there is yet to be a universal standard in the frontend
world, or it’s just a bad programming habit. Frontend applications should
not be treated too differently from regular software applications. In the
frontend world, you still use separation of concerns in general to arrange
the code structure. And all the proven useful design patterns still
apply.
Welcome to the real world React application
Most developers were impressed by React’s simplicity and the idea that
a user interface can be expressed as a pure function to map data into the
DOM. And to a certain extent, it IS.
But developers start to struggle when they need to send a network
request to a backend or perform page navigation, as these side effects
make the component less “pure”. And once you consider these different
states (either global state or local state), things quickly get
complicated, and the dark side of the user interface emerges.
Apart from the user interface
React itself doesn’t care much about where to put calculation or
business logic, which is fair as it’s only a library for building user
interfaces. And beyond that view layer, a frontend application has other
parts as well. To make the application work, you will need a router,
local storage, cache at different levels, network requests, 3rd-party
integrations, 3rd-party login, security, logging, performance tuning,
etc.
With all this extra context, trying to squeeze everything into
React components or hooks is generally not a good idea. The reason is
mixing concepts in one place generally leads to more confusion. At
first, the component sets up some network request for order status, and
then there is some logic to trim off leading space from a string and
then navigate somewhere else. The reader must constantly reset their
logic flow and jump back and forth from different levels of details.
Packing all the code into components may work in small applications
like a Todo or one-form application. Still, the efforts to understand
such application will be significant once it reaches a certain level.
Not to mention adding new features or fixing existing defects.
If we could separate different concerns into files or folders with
structures, the mental load required to understand the application would
be significantly reduced. And you only have to focus on one thing at a
time. Luckily, there are already some well-proven patterns back to the
pre-web time. These design principles and patterns are explored and
discussed well to solve the common user interface problems – but in the
desktop GUI application context.
Martin Fowler has a great summary of the concept of view-model-data
layering.
On the whole I’ve found this to be an effective form of
modularization for many applications and one that I regularly use and
encourage. It’s biggest advantage is that it allows me to increase my
focus by allowing me to think about the three topics (i.e., view,
model, data) relatively independently.
Layered architectures have been used to cope the challenges in large
GUI applications, and certainly we can use these established patterns of
front-end organization in our “React applications”.
The evolution of a React application
For small or one-off projects, you might find that all logic is just
written inside React components. You may see one or only a few components
in total. The code looks pretty much like HTML, with only some variable or
state used to make the page “dynamic”. Some might send requests to fetch
data on useEffect after the components render.
As the application grows, and more and more code are added to codebase.
Without a proper way to organise them, soon the codebase will turn into
unmaintainable state, meaning that even adding small features can be
time-consuming as developers need more time to read the code.
So I’ll list a few steps that can help to relief the maintainable
problem. It generally require a bit more efforts, but it will pay off to
have the structure in you application. Let’s have a quick review of these
steps to build front-end applications that scale.
Single Component Application
It can be called pretty much a Single Component Application:
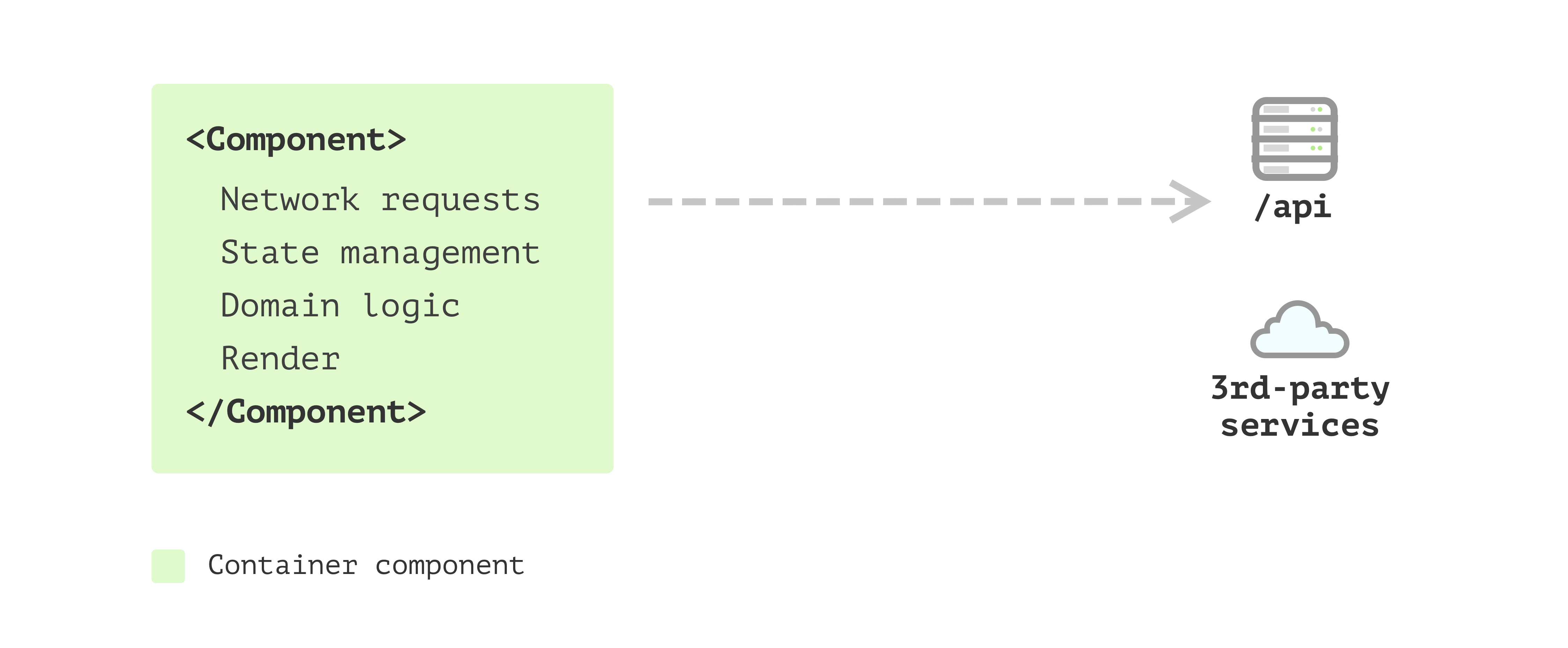
Figure 1: Single Component Application
But soon, you realise one single component requires a lot of time
just to read what is going on. For example, there is logic to iterate
through a list and generate each item. Also, there is some logic for
using 3rd-party components with only a few configuration code, apart
from other logic.
Multiple Component Application
You decided to split the component into several components, with
these structures reflecting what’s happening on the result HTML is a
good idea, and it helps you to focus on one component at a time.
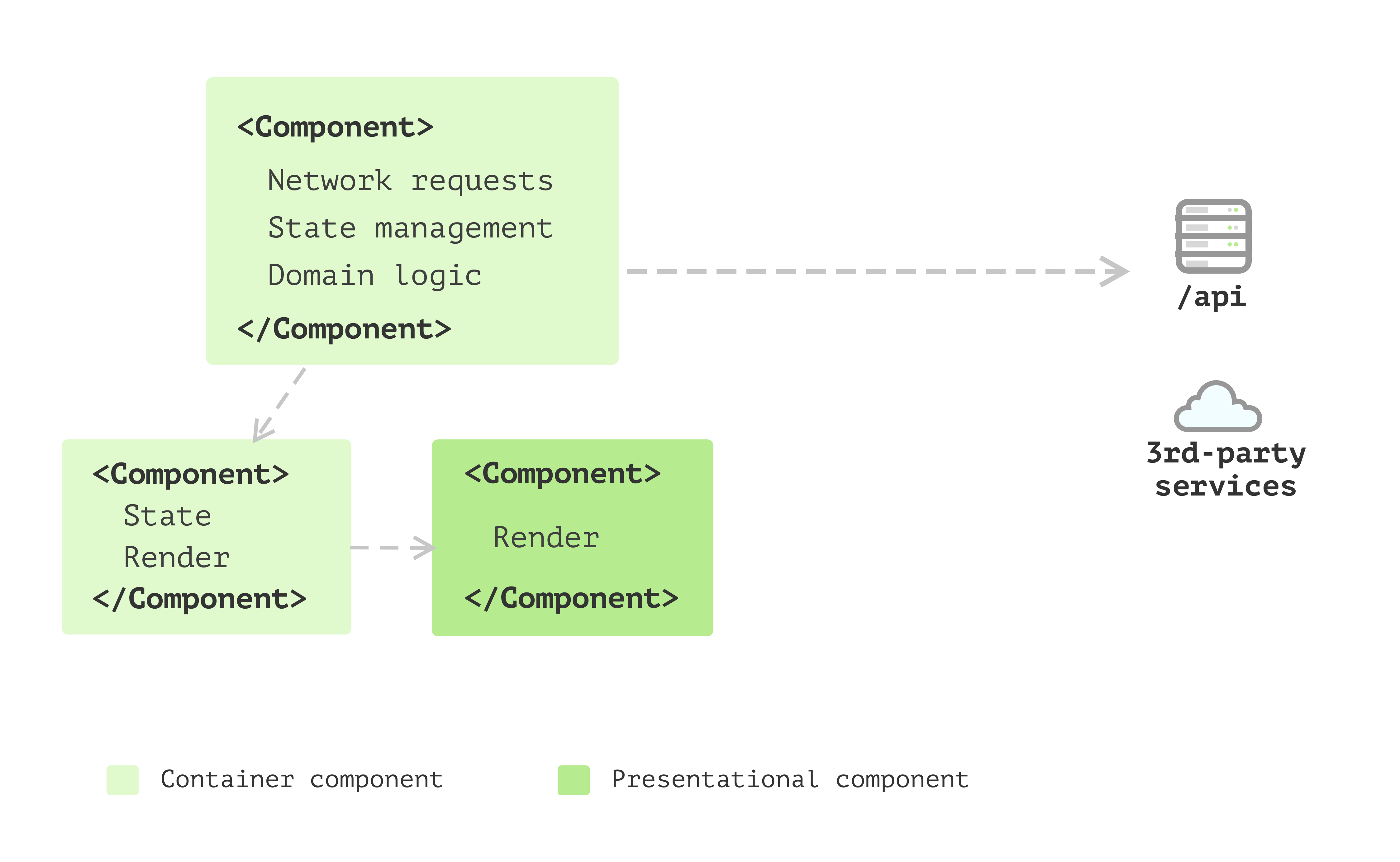
Figure 2: Multiple Component Application
And as your application grows, apart from the view, there are things
like sending network requests, converting data into different shapes for
the view to consume, and collecting data to send back to the server. And
having this code inside components doesn’t feel right as they’re not
really about user interfaces. Also, some components have too many
internal states.
State management with hooks
It’s a better idea to split this logic into a separate places.
Luckily in React, you can define your own hooks. This is a great way to
share these state and the logic of whenever states change.
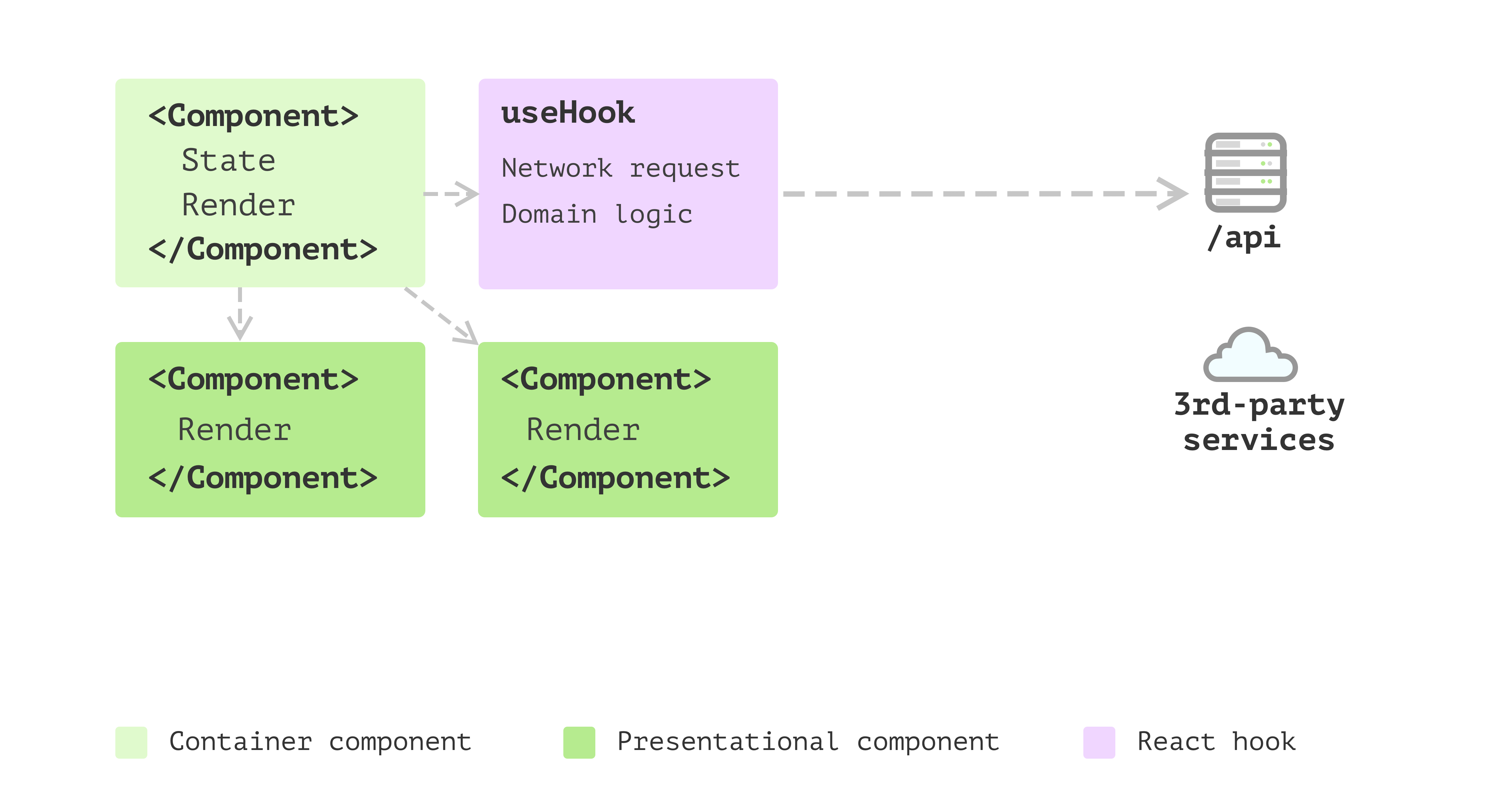
Figure 3: State management with hooks
That’s awesome! You have a bunch of elements extracted from your
single component application, and you have a few pure presentational
components and some reusable hooks that make other components stateful.
The only problem is that in hooks, apart from the side effect and state
management, some logic doesn’t seem to belong to the state management
but pure calculations.
Business models emerged
So you’ve started to become aware that extracting this logic into yet
another place can bring you many benefits. For example, with that split,
the logic can be cohesive and independent of any views. Then you extract
a few domain objects.
These simple objects can handle data mapping (from one format to
another), check nulls and use fallback values as required. Also, as the
amount of these domain objects grows, you find you need some inheritance
or polymorphism to make things even cleaner. Thus you applied many
design patterns you found helpful from other places into the front-end
application here.
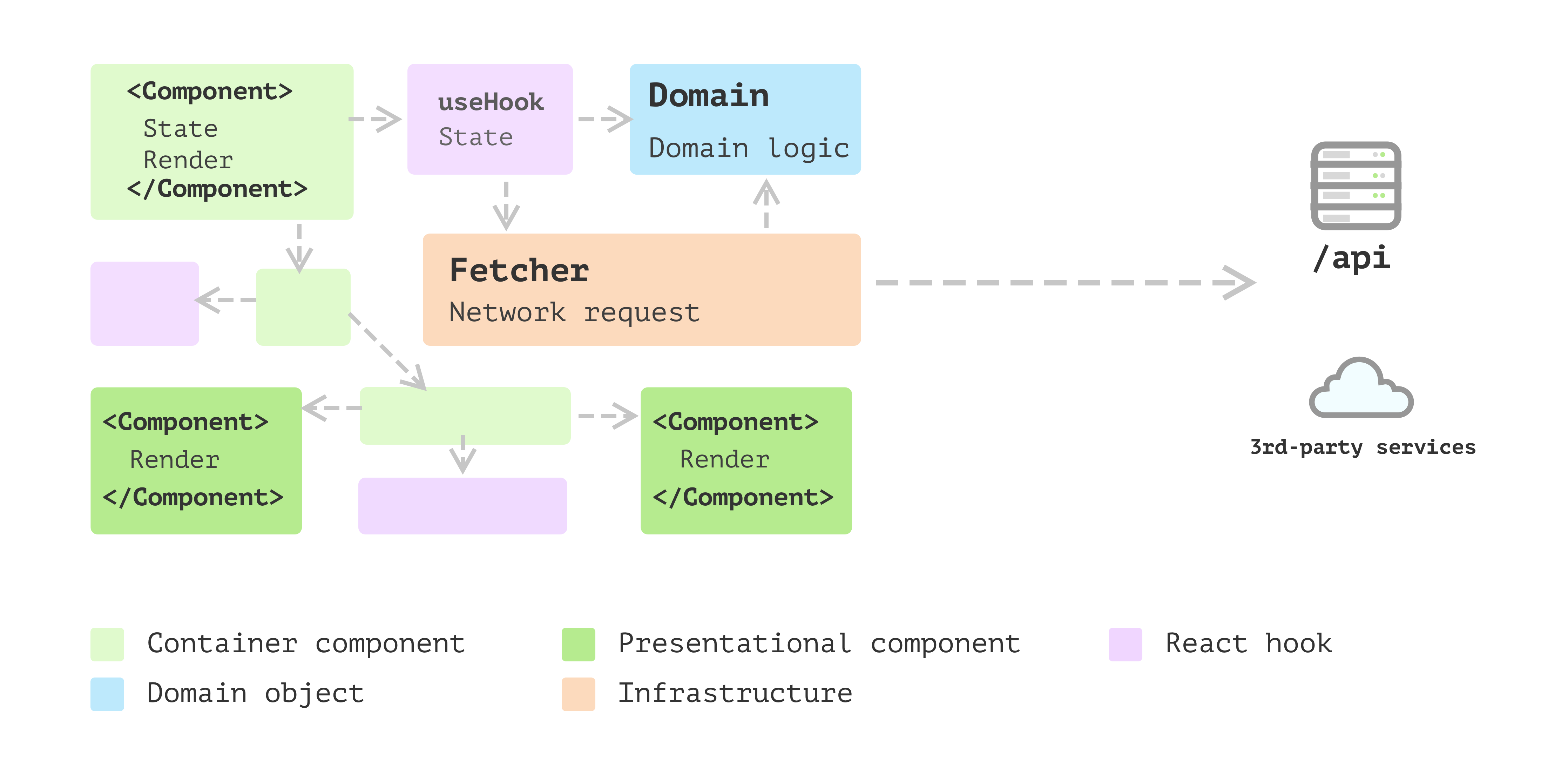
Figure 4: Business models
Layered frontend application
The application keeps evolving, and then you find some patterns
emerge. There are a bunch of objects that do not belong to any user
interface, and they also don’t care about whether the underlying data is
from remote service, local storage or cache. And then, you want to split
them into different layers. Here is a detailed explanation about the layer
splitting Presentation Domain Data Layering.
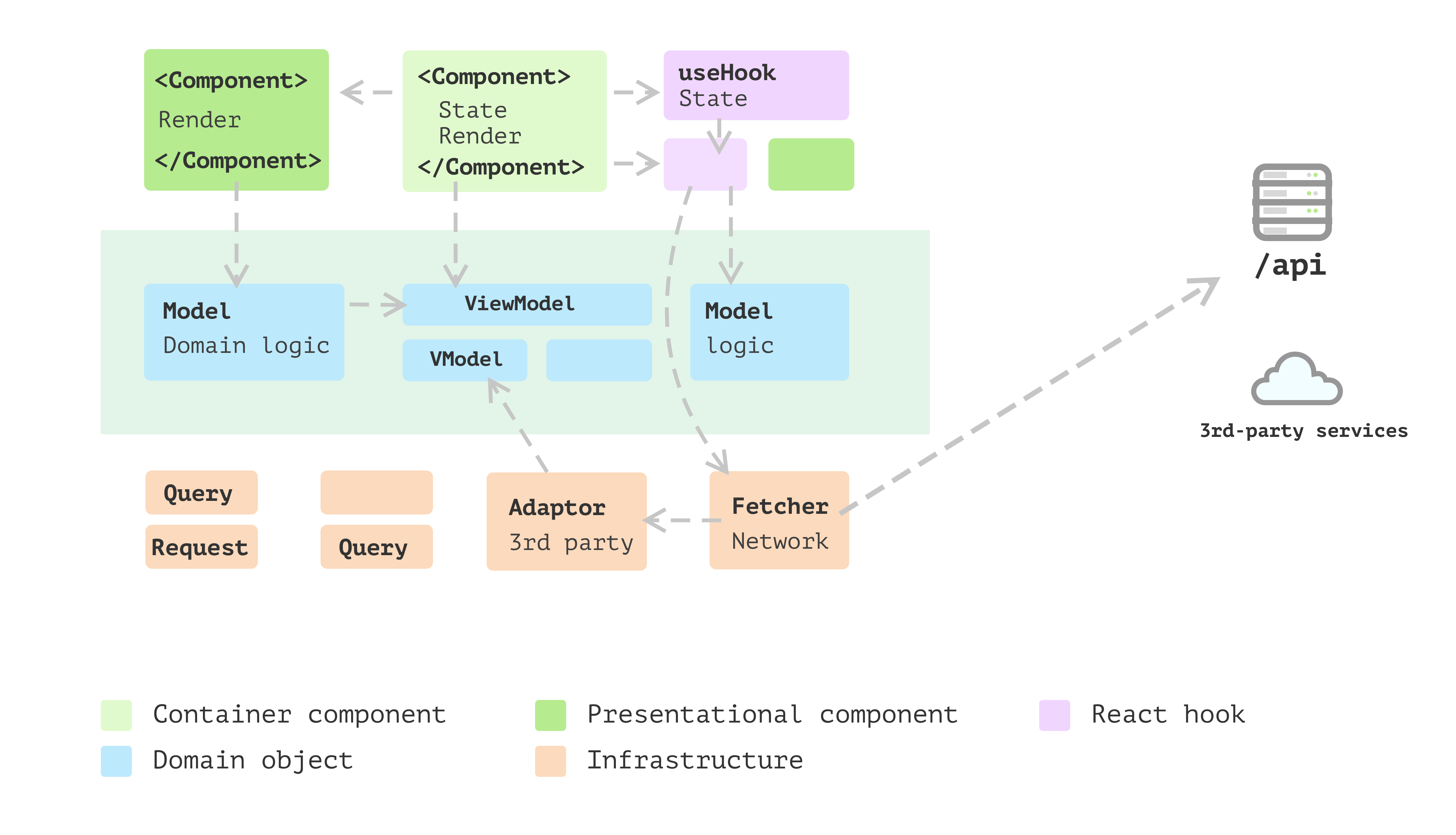
Figure 5: Layered frontend application
The above evolution process is a high-level overview, and you should
have a taste of how you should structure your code or at least what the
direction should be. However, there will be many details you need to
consider before applying the theory in your application.
In the following sections, I’ll walk you through a feature I
extracted from a real project to demonstrate all the patterns and design
principles I think useful for big frontend applications.

{kind=link}